Simple DQMH Do's and Don'ts

Today’s post consists of some simple do’s and don’ts in order to get the most out of using the DQMH. The DQMH is a great tool, but like any tool, if you misuse it, you can create a mess. In a previous post, I mentioned Developer Dan (who actually happens to be a CLA). I recently inherited a project from Dan (names have been changed to protect the guilty) and let’s just say he showed me a lot of ways that you can misuse the DQMH. I figured if a CLA ran into some problems, then perhaps other people might be running into similar problems. So my goal in this post is to share all the lessons I learned from Dan with you all so that hopefully you can avoid some of the same mistakes.
This is intended as a supplement to the DQMH best practices found here. These are general guidelines, you certainly don’t have to follow them (except the first one, you really should try to understand the framework). If you have a good reason not to follow them, then that is fine, just make sure you understand the consequences and document what you are doing and why.
Do Understand Your Framework
No matter what framework you use, it is important to understand the model that it is based on. The DQMH is loosely based on something called the actor model. In the actor model the whole program is broken down into actors (this is one point where the DQMH differs a little bit – DQMH plays nice with other coding styles – everything does not have to be a DQMH module). Each actor is a completely separate entity with its own state. Think of it as its own separate loop or process. The only way the actors interact with each other is by sending messages to each other (no other communication channels). In response to a message an actor can: 1) Send a message to another actor 2) launch another actor or 3) change its state. Since actors are independent, a particular actor can’t control when it might receive a specific message from another actor, therefore at any point in time, it should be able to handle any message.
In applying the actor model to the DQMH, each module can be thought of as an actor. The Request and Broadcast events are the messages sent between the actors. And lastly, the state data is the data passed around in the shift register in the MHL (See below).
Terminology
In order to talk intelligently about the DQMH, we need to make sure we are all on the same page as far as terminology:
- Application Programming Interface (API) – This how the rest of your program interacts with your DQMH module. It consists of the public VIs in a module’s library. It consists of VIs to start and stop the module and to send request events and register for broadcast events.
- Request Events – These are the events that the outside world fires in order to request that a module does something. The word request in the name is important. The outside world can send a request message, but ultimately the module itself can decide to honor it or not, depending on its current state. Each request event has an associated API VI to fire the event.
- Broadcast Events – These are the events that a module can broadcast to the outside world. There is an API VI which will return a cluster of refs so that outside code can register for the events. For each broadcast event, there is a private VI for firing the event from inside the module.
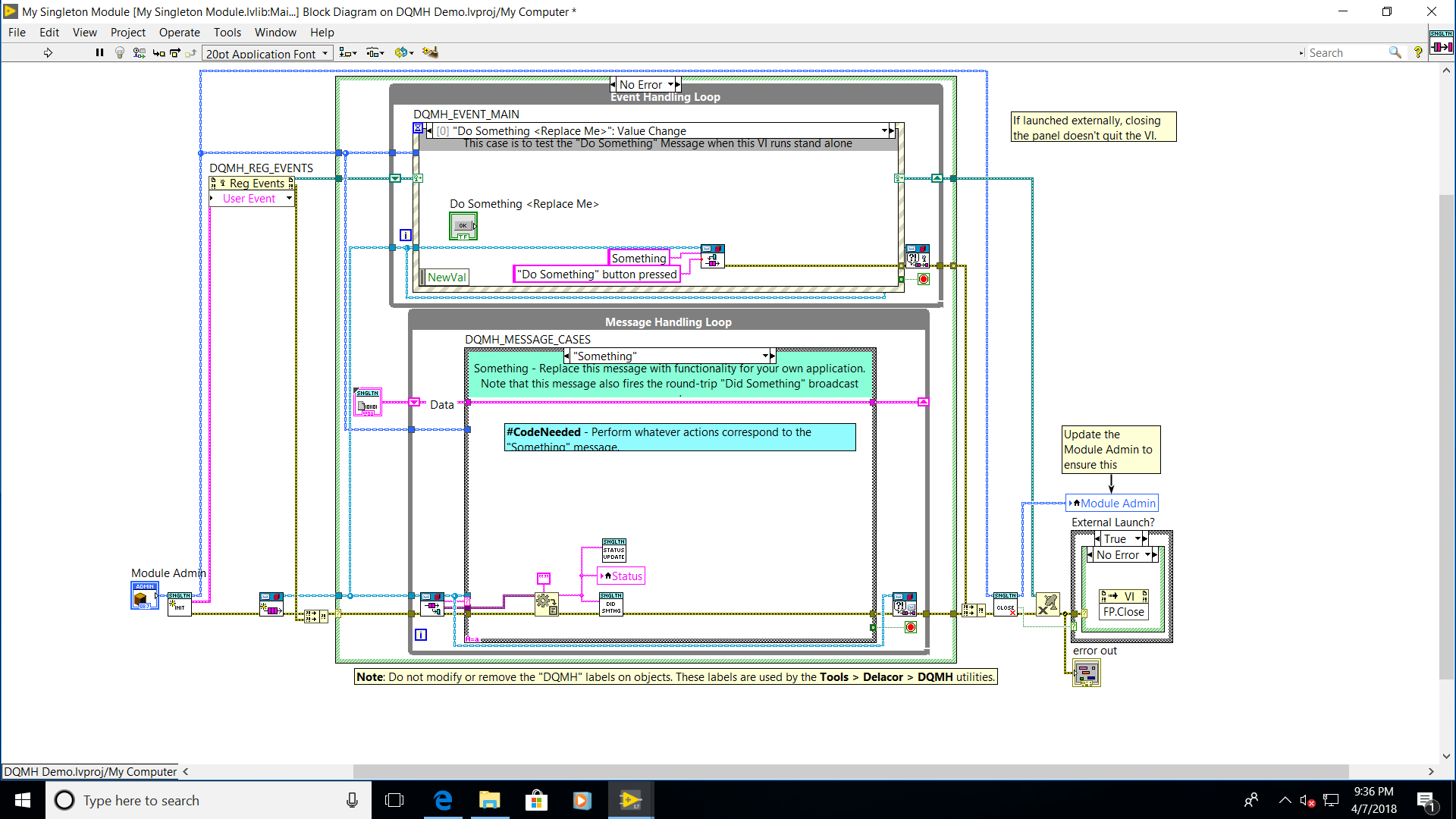
- Event Handling Loop (EHL) – In the main VI this is the upper loop with the event structure.
- Message Handling Loop (MHL) – in the main VI this is the bottom loop with the dequeue and the case structure.
Here is a screenshot of the main VI showing the EHL and MHL labeled.
 s
s
General Flow of Messages within a module
When the DQMH module is launched and after some overhead, such as creating the queue ref and event refs, the main VI is launched. By default, it basically just sits there until the module gets a request event, front panel event, or perhaps a broadcast event from another module. The event is first received in the EHL. The EHL then enqueues a state to the MHL to handle the event (usually it has the same name as the request event). It also bundles in any data that comes with the event. Then the EHL waits for the next event. That sent message is dequeued in the MHL and the appropriate case is executed. The state data that is passed around in the shift register in the MHL can be updated as needed. For sending data to the outside world broadcast events are used. They can be fired anywhere within the module, at any time.
Do be very cognizant of coupling
I highly recommend you layout your modules ahead of time in a tree type structure similar to the actor tree model that is common the Actor Framework. See image below (replace Actor with module)
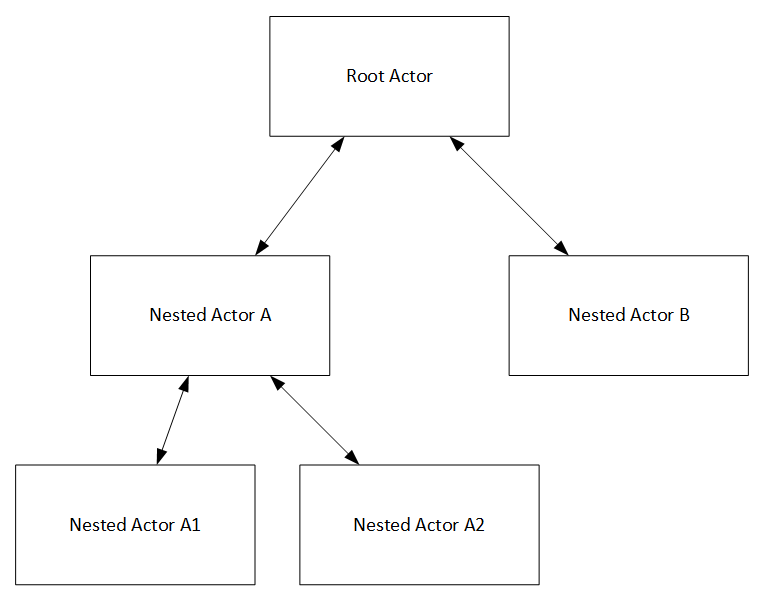
You should set up your communication to go up and down the tree from parent to child. You should not skip generations (ie. directly from root to A1) or talk directly to siblings (ie from A to B). This is a general recommendation. You may find a case where you need to break this. Do so carefully.
Why do we do this? If we set up our modules this way and send messages between them in the correct way it will make your modules reusable. Each module will only know about and depend on the modules underneath it. If a module knows nothing about what is above it (and doesn’t care), it is very easy to take it out and drop into the tree for another project. For example, if we set things up correctly, we can take module A above (along with A1 and A2) and reuse that in another project as-is with no changes. Drap and Drop. Done. We don’t have to drag around the root module or module B.
So how do we achieve this with the DQMH? Let’s look at Module A (and you can repeat this for any of the other modules). The only module that should depend on A, is its parent in the tree, the root. The root can call the VIs to start and stop A. It can also send data down to A, by calling the Send Request VIs. It can also register for all the Broadcast events that A can generate. These all require that root knows about A, but do not require A to know anything about root. In this way, data flows down the tree via request events and up the tree via broadcast events, and A has no idea who or what is above it in the tree and doesn’t care. It can be used in whatever project you would like without dragging around any of the other parts of the project except its part of the tree (ie. itself, A1 and A2).
REMEMBER
- Down the tree = parent sends request events to child
- Up the tree = parent registers for child’s broadcast events
Do make helper loops reusable.
If reuse is a good thing and we make our modules reusable, we should also make our helper loops reusable, so we can easily reuse them in different modules. How do we do this? We manage dependencies. We need to be very careful that our helper loops depend on generic datatypes and common VIs and not on a particular module. A very easy way to check this is to create a blank project. Add your helper loop and then look in the dependencies section. If you see any DQMH modules, then your helper is not reusable without dragging those modules around.
Every helper loop will generally need at least 2 things. If we are smart about how we implement these 2 things, we can create helper loops that can be dropped into any DQMH module. The 2 things are:
- A way to send data to the module – I recommend you simply use the queue. There is no need to go through the EHL. The helper loop is part of the module, so you are not breaking encapsulation by sharing the queue. The queue reference is generic to all DQMH modules and the queue type is a string and variant, so that won’t tie you to a specific module either. If you make the mistake of firing request events in here and going through the EHL, you will tie your helper loop to a specific module. For any commands you send, if you send data, make sure the typedef is not part of a module’s library or that will also tie your helper loop to the module.
- A way for the module to communicate with the helper loop – I recommend using events. At a minimum, there is a “Module Did Stop” broadcast event that every DQMH module has. You should register for this and use that to stop your helper loop. Don’t call the module’s “Get Broadcast Events” inside your helper loop, but call it outside and pass the reference in via the connector pane. I recommend registering for the “Module Did Stop” event regardless of whether you have a separate stop mechanism. It will prevent your program from hanging when the module stops. Pay very careful attention to when the “Module Did Stop” event fires. This will dictate that you should place your helper loop outside the error case that encloses the EHL and MHL. If you are going to pass an error out, be careful where you wire it up. I recommend just sending the error to the MHL to handle instead and not passing anything out of your helper loop. Another trick here is that for some reason if you copy the “Module Did Stop” ref from a module, the typedef inside the event ref is not generic. It is linked to a typedef inside the module’s library. The fix is to right-click on the event ref > show control. Then right-click on the control inside the refnum > disconnect from typedef. If you generate other events to control your helper loop, I recommend you just generate them all manually and manage them manually and definitely keep them local to the module.

Don’t perform extra processing or maintain state in the EHL
The EHL should really only respond to 3 things:
- Request Events for that module
- Front Panel Events that occur in the main VI for that module
- Broadcast Events from other modules (be careful with coupling)
You should avoid doing any processing or making any decisions in the EHL. The only thing that the EHL should do when it receives an event is forward it to the MHL. You should not have any need for a shift register in the EHL… Store that state data in the MHL and let it decide.
Do make MHL actions atomic
What do I mean by atomic? I mean that if you want one case of the MHL to call another immediately, you should do it in such a way that no other case can execute in between. As an example: Say I have a module with Read Data and Update Display cases. I may want to be able to call each of these separately and they may each be attached to a Request Event. What if I want to Update Display immediately after I finish Read Data?
Developer Dan’s solution was just to call the “Update Display” Request Event. This would throw an event on the event queue in the EHL loop, which would then enqueue the message to the MHL. In the meantime, someone else could fire an event or drop something in the queue. Also going through the EHL added zero value. In addition, it added a bunch of request events that the rest of the world could call and that didn’t really make sense.
The next best solution would be to have the Read Data case directly enqueue the Update Display Case. It is better, but in the meantime, someone else could still fire an event and have something dropped in the queue, or a helper loop could drop something in the queue.
Neither of those solutions is atomic. The best solution is to encapsulate everything that happens in the Update Display Case with a subVI and have the Read Data case simply call that subVI at the end. Then you are longer dependant on the EHL or MHL queue. Nothing else can execute between the 2.
Don’t Enqueue inside of MHL
Makes things non-atomic – see above.
Do make every MHL case a subVI
This allows for atomic actions. See above.
Edit: There has been some debate over this. After talking to Joerg, he asked me to clarify a little bit. My intent with this point was make it easier to make the MHL cases atomic. Say you start with messages A and B and each case consists of executing one subvi. If you want a message “Do A then B” you could just chain the 2 subvi calls in that case. That would make it atomic, in that nothing else could happen in between A and B. However, now you have a case with 2 subvi calls in it, which would kind go against my own advice of make every MHL case a subvi. You could combine those into 1 subvi that simply calls A and B. However Joerg’s point was that hides too many details and I agree. Also you may want to do some UI manipulation that may be easier to do on the block diagram and not in subvi. I would reword this advice as Keep MHL Cases Simple. You should strive to have them be 1 or 2 method calls and maybe 1 or 2 property nodes if you need to manipulate some UI stuff. It makes them easier to debug and easier to combine 2 cases if you need to make something atomic.
Do consider making state data a class
If we are making every case a subVI see above) and they are all using/modifying the same cluster of data, then it is very easy to convert that to a class. This offers some benefits, notably inheritance (very useful if you want to make a Hardware Abstraction Layer or HAL). You can also take that nice packaged class and use it elsewhere.
Edit: There has been some debate over this and I have since changed my mind slightly. Fab has suggested, and I agree, that a better course of action is to add a class to the private data. This allows you to keep UI specific stuff, like control refs, separate from the class data. It gives you more flexibility. I also want to point out that adding a class helps with unit testing. It helps you avoid the temptation to try to test private VIs. The class instance can be private to the module, as in it resides in the shift register and there is no way for something outside the module to set it. However you can make the class itself public and then it becomes very easy to write unit tests for its methods.
Do maintain state only in MHL
Maintaining state in the EHL or helper loops should be avoided at all cost. If you do, synchronizing it all will create many problems, such as race conditions. If you find yourself doing this, consider making the helper loop its own DQMH module.
Edit: After talking to Chris Farmer, I decide this could be better worded as “Don’t store the same mutable state in multiple places”. The issue really is the updating and keeping things synced. So if the data is immutable, like for example configuration data you read once in the beginning of your program and never change, then there is no issue with having it float around in multiple shift registers.
Do route everything through the MHL
Because the MHL maintains state for the module everything that could affect the state of the module should pass through here so that the state can be updated accordingly and so that any decisions can take the current state into account. Even for an action that doesn’t interact with the state data now, you may change your mind about that in the future so I recommend routing everything through here. What do I mean by that? I mean every piece of data entering or leaving the module should go through here. Request events should be forwarded by the EHL. Broadcast events should only be fired from within the MHL. As mentioned before helper loops should not fire broadcast events, they should use the queue to communicate with the MHL, which can fire the event. This decouples the helper loop.
Don’t communicate directly between EHL and helper loops
See preceding point.
Don’t make a Request Event every time you need a new case in the MHL
It is ok, even desirable to have cases in the MHL that are not linked to a Broadcast Event. There are times when you need a case and you don’t want the outside world to be able to call it whenever they would like (via a request event). For some reason Developer Dan seemed to think that every time he wanted a new case, he had to create a new request. It is ok to right-click on the case structure and click add a new case. Don’t clutter your API with a bunch of “internal” events.
Do be prepared to handle any message at any time (and in any order)
Try to avoid situations where cases in the MHL have to happen in a particular order. Remember the module has no control over when messages are sent to it and in what order. Imagine you had 2 cases: Configure DMM and Read DMM. Presumably, the DMM needs to be configured before you can read from it. A simple solution is to have a flag in the state data that indicates whether the DMM has been configured. Then in the Read DMM case, if it has not been configured you can either ignore the command or throw an error. A perhaps more elegant solution is to just define some default configuration and if a configuration hasn’t been set, just use that. Or another elegant solution might be to pass the configuration at the same time you ask for a reading and combine the Configure DMM and Read DMM into one case.
Do pass static initialization data directly when launching module
In most modules, you will likely have some static initialization data. Perhaps it is some configuration data or some paths that aren’t going to change while the module is running. You could add a “Configure” request event and send those to the module. The downside is A.) that the module is dependant on the calling code to send it a configuration. B.) The calling code could potentially send that message at a later date. C.) Some other messages that require the configuration data, could get sent before the configuration gets set. Handling all these situations would require keeping track of and checking a lot of flags. There is a simple solution. I’ll leave that as an exercise for the reader (HINT: Look at next paragraph).
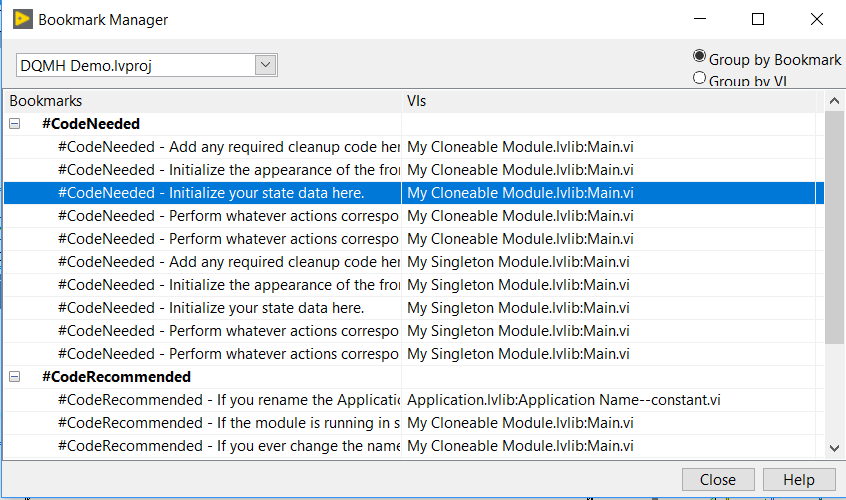
Do pay attention to the #CodeNeeded and #CodeRecommended tags
Delacor spent a lot of time putting these tags throughout the code at important spots. Take advantage of them. If you are having trouble figuring out where the best spot is to do something, check out the bookmarks. It’s probably already marked. To view bookmarks goto View>Bookmark Manager. Click on a bookmark in the list and it will take you to that point in the code.