Navigating a git repository

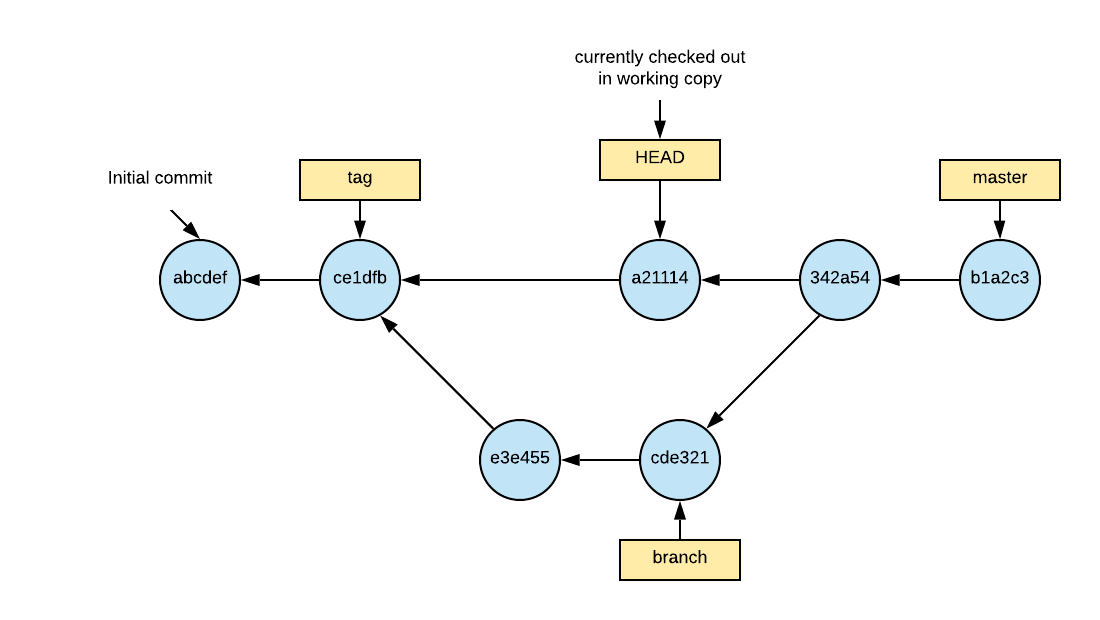
Navigating the Commit Graph
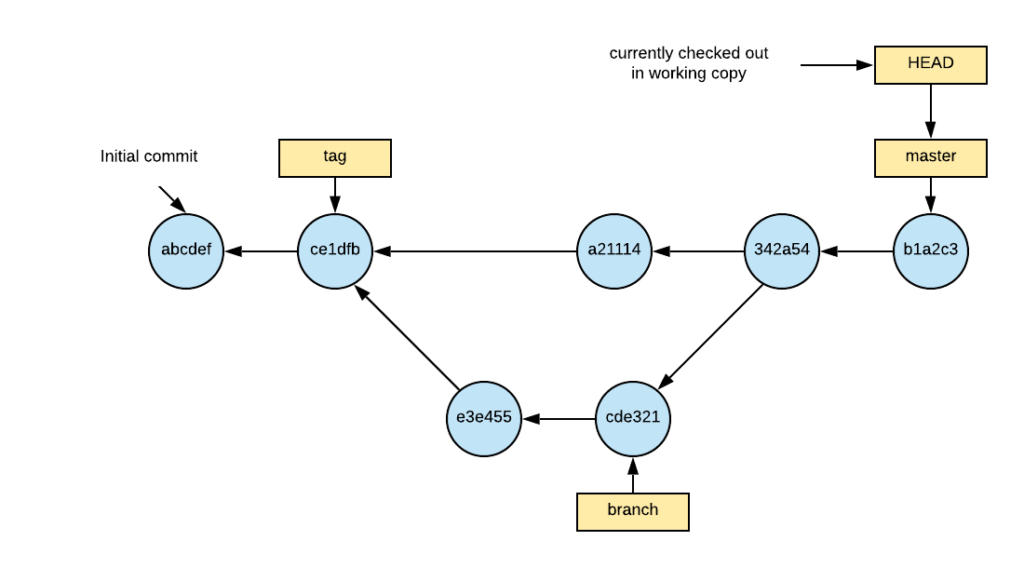
Sometimes we want to go back and revisit a particular commit in our project. We might want to do that for a variety of reasons:
- Maybe a customer reports a bug in a specific version. We might go check out that tag to reproduce the bug.
- Perhaps we want to create branch starting at some past commit
- Maybe we want to throw away some recent commits because whatever feature we added in the last few commits didn’t work out.
- Maybe there was a file that was deleted a few commits back and we want to go see what was in it.
- Maybe we want to switch to another branch to continue development there.
- Maybe we want to undo a merge.
The main commands in git for revisiting past commits are git reset, git checkout, and git switch. They are sometimes confused but they each behave differently and have different use cases. We will also talk a little about git restore which is used to update a file’s contents to what it was at a particular commit.
Checkout
Checkout is used to manipulate the HEAD ref and point it directly to a different commit.
The History of Checkout
If your version of git supports the git restore and git switch commands, feel free to skip the next 2 paragraphs.
Checkout is also overloaded with several other functionalities as well. Many of those have been replaced with other functions in the most recent version of git. I mention all this not to confuse you, but so that you aren’t confused if you happen to be using or encounter an older version of git, or if you see some old posts in Stack Overflow. I will use the newer commands for the rest of the article.
Here are some of the older deprecated uses of checkout. It can be used to switch to a different branch: git checkout otherbranch or create a branch: git checkout -b newbranch. That functionality has been replaced by the git switch command. Checkout was also used to replace a file with a previous commit of the same file: git checkout commitID -- file. This command was most often used to discard changes in your working copy: git checkout -- file since the default commit ID is HEAD. This has been replaced with the git restore command. The old commands are still available for backwards compatibilty.
Checkout a commit or a tag
The use of checkout we are going to talk about is to checkout a specific commit or tag – git checkout CommitIDOrTag. In either case, what happens is that the HEAD ref is updated to point to a specific commit directly (no branches or tags involved). if HEAD was pointing at a branch, that branch ref stays put. Once the HEAD is moved, the working copy and index are updated to match the contents of that specific commit. Untracked files aren’t touched (ie. they stay in your working directory). If you have a dirty working directory (uncommitted changes) then the switch will fail. More on that in the section on stashing.
checkout a21114

checkout tag
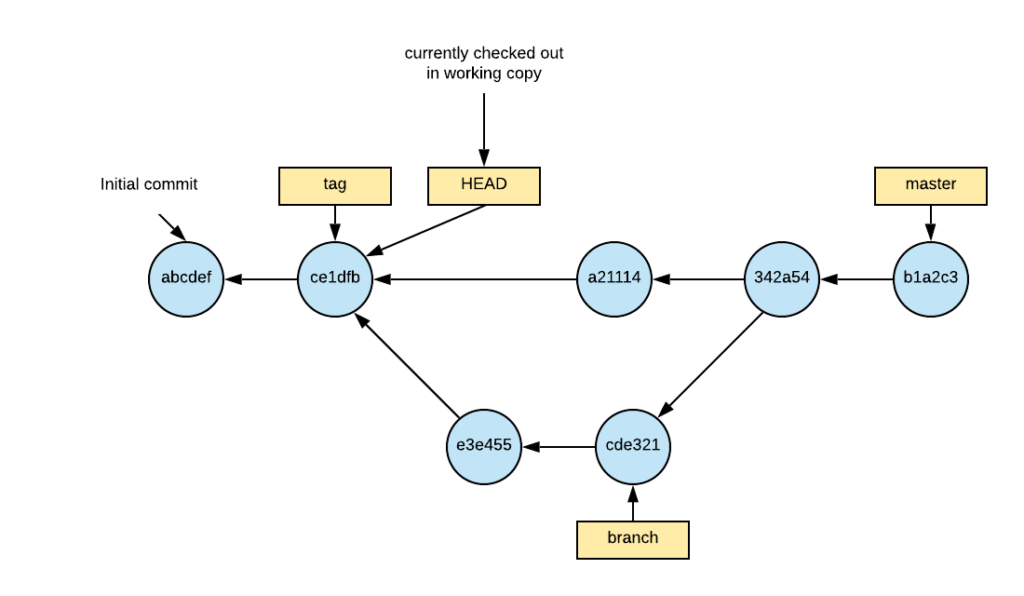
Fixing a Detached Head
Once you use checkout to check out a tag or commit ID, you will be greeted by a Detached HEAD message. Don’t worry it is not as dire as it sounds. In git world, unlike the real world, you can survive with a detached HEAD. All it really means is that the HEAD is pointing directly at a commit rather than a branch. The warning is there because if you were to make a commit now, you could potentially lose work.
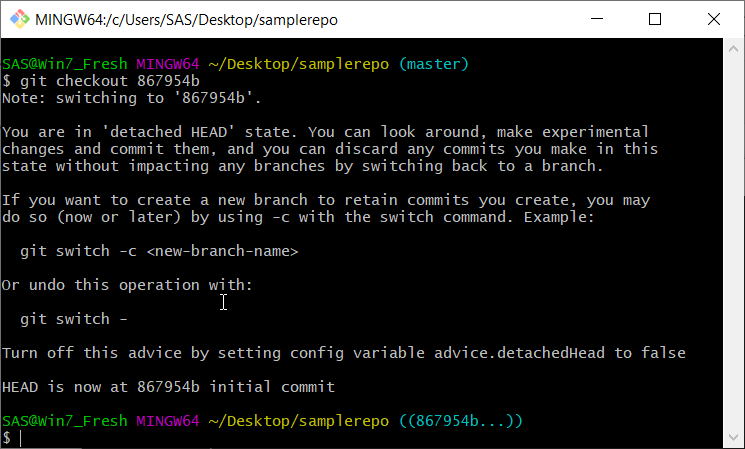
Here is how you could lose data. If you make a commit, the HEAD will now point to that new commit. However, if you then move the HEAD somewhere else (with checkout, reset, switch or some other method) then that commit will be orphaned if there is nothing else pointing to it. If it is orphaned, eventually git’s garbage collection will delete it. If you catch it before garbage collection gets it, you can get it back. In this case, the reflog is your key to finding orphaned commits. I will probably do a post on that later.
# create commit on detached head
git commit -m"create commit b12c124f"
# then switch to master branch will move HEAD to master and leave previous commit orphaned
git switch master
Switching
The detached HEAD message helpfully tells you how to get out of a detached HEAD state using the switch command. One option is to create a branch where you are in order to save any commits you made on the detached HEAD using git switch -c newbranch. The other option is to switch to some other branch and potentially lose any commits you made on the detached HEAD using git switch -. This command will check out the last branch you had checked out before you went into the detached head state. To switch to some other arbitrary branch use git switch otherbranch.
What happens behind the scenes when you issue these commands? When you use git switch -c the only thing that happens is that a new branch ref is created that points to the commit you currently have checked out and HEAD is set to point to that. The Working Directory and the Index are not touched, so it will succeed even with a dirty working directory.

If you use switch to switch to an existing branch, then the HEAD is moved and the working copy and index are updated to match the commit that the branch points to. Untracked files are left alone. If you have a dirty working directory (uncommitted changes) then the switch will fail.
Stashing
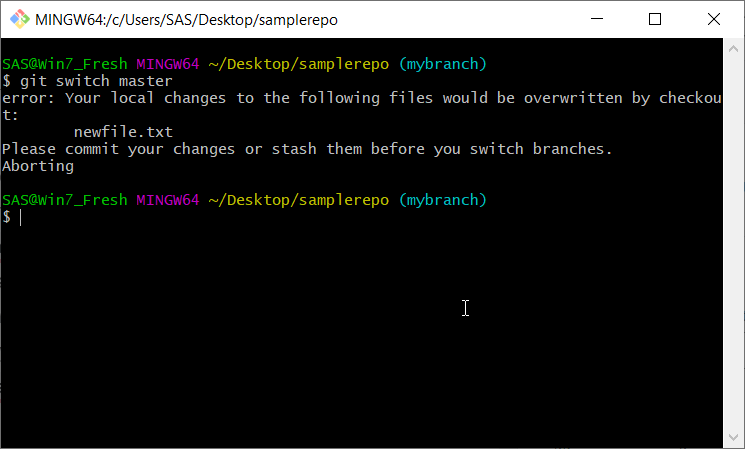
When checking out or switching branches, you will see the above error if you have a dirty working directory. This is git protecting you to make sure you don’t lose any uncommitted changes. Any changed files would get clobbered when git updates your working copy and index to match the new commit. So git won’t let you do it. The easy answer is to follow the instructions and simply commit your changes. You could also discard them using git restore. However if you wish to keep the changes but not commit them right now, there is another way: stash.
Think of the stash as just a local stack that you can push some changes onto. It holds onto them and later you can pop them back off when you want them. git stash pushes any changes you have made to your working copy or index to the stash. By default this does not grab new untracked files. If you want those out of your way add then add a -u. Use git stash pop to pop your changes back off and into your current working copy.
Reset
Whereas git checkout moves the HEAD itself, git reset moves the branch that HEAD points to. git reset should be used with caution. It can cause you to orphan commits. It can also cause you to lose changes in your working copy if you use the --hard option. Also you should avoid using reset on any branches you have pushed to another repository since you are altering history.
There is another difference between checkout and reset. That has to do with what happens to the index and working copy. With checkout and switch, the working copy and index are updated to reflect the state of the newly selected commit. git reset has 3 different options to determine what to do with the index and working copy. Before reading the next section, you may want to review the working copy and index. Remember the index is a snapshot, not a list of changed files.
Soft Medium or Hard?
Using git reset --soft will move the branch pointer without touching the index or working copy. Using git reset --medium is the default behavior. The index is reset so any staged changes are no longer staged. Your working copy is left alone so any changes in your working copy are still there. git reset --hard behaves similarly to git switch or git checkout in that the working copy and index are updated to match the newly selected commit.
Git reset is most often used when we want to undo a commit. We just made a commit and we decide we want to go back for some reason. Let’s look at some examples.
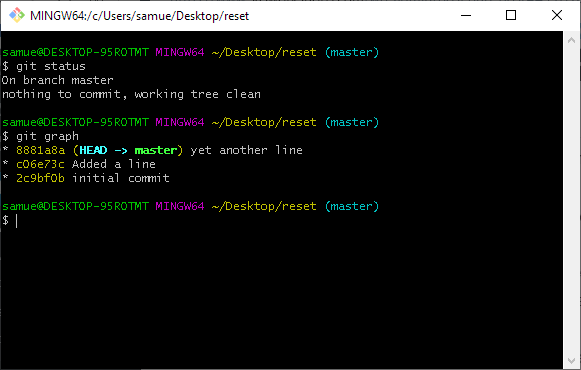
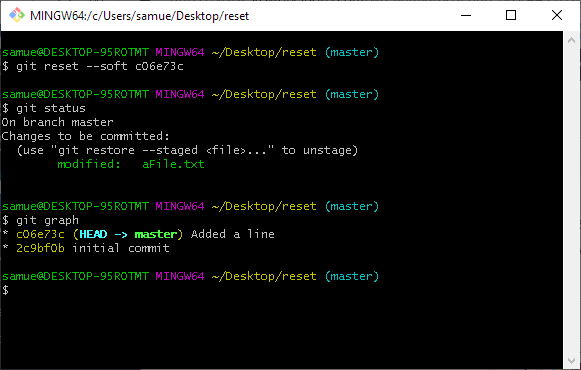
git reset --soft. Soft does not touch the index or working copy. Remember the index is a snapshot. It was a snapshot of the previous commit (plus whatever we may have added to it – in this case nothing). Hence after the reset, there are some changes in the index that are not in the commit that HEAD is pointing to now, hence the changes are staged and ready to be added in our next commit.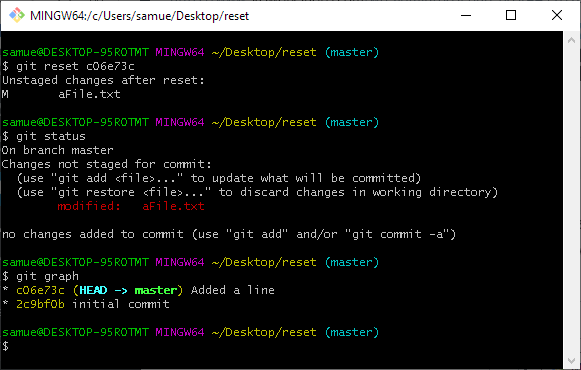
git reset type is medium. It resets the index to represent the new position of the HEAD, but does not touch the working copy. Hence the edits to aFile.txt are still present in the working directory but not the index.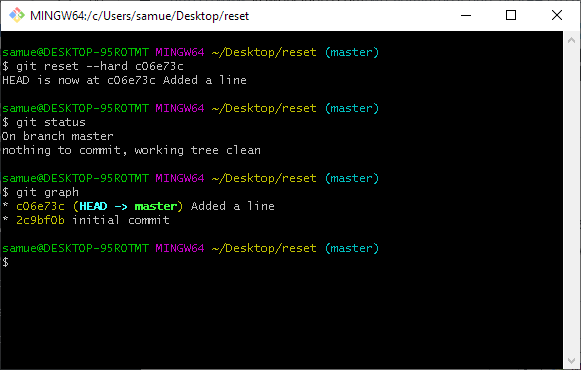
git checkout or a git switch command, git reset --hard resets the index and working copy to match the new commit. Unlike git checkout or git switch, you can git reset --hard when you have uncommitted changes in your working copy or index. They just disappear. Hence use --hard with caution. Any untracked files are left alone.Checkout, reset or switch?
So when to use what command?
| What are you trying to accomplish? | Command |
| Explore a previous commit or tag | git checkout |
| Undo commit(s) or merge(s) completely | git reset --hard |
| Undo commit or merge but keep changes to the working copy. | git reset (add --soft to keep index as well) |
| Switch to another branch | git switch (replaces git checkout for branches) |
| Create a new branch | git switch -c (replaces git checkout -b) |
| Set a file’s contents to what it was in a particular commit | git restore (replaces git checkout for files) |
| Temporarily stash some uncommitted changes for later so you can switch branches or checkout a commit | git stash add -u to grab untracked files as well |
| Retrieve stashed changes | git stash pop |
