Character Sets


So here is another article inspired by Joel on Software. In this article, titled The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!), Joel talks about the importance of understanding Unicode and character sets. It is a bit of a rant (Joel is somewhat famous for those).

I think this article is somewhat timely. One of the big reasons cited for creating LabVIEW NXG was to add Unicode support. Apparently, regular LabVIEW doesn’t handle Unicode very well. I am sorry to admit that before NXG came around, I wasn’t really aware of the issue. Being a typical American and working for an American company, it was not something that ever came up. We never had to localize any of our applications so everything was always just straight ASCII.
There ain’t no such thing as plain text.
According to Joel, this is the most important thing to understand about encodings: “There ain’t no such thing as plain text.” The way I think about this is that if someone gave you a bunch of binary data (1’s and 0’s), and told you it represented a number, that still wouldn’t be enough information. You’d still need to know if it is an I32, U32, single, double, etc. You need to know how to interpret it in order to make sense of it and be able to use it. It is the same if someone told you those bits represented some text. You can’t just assume it is ASCII, you have to know the encoding.
A Character is a Code Point, Not a Byte
My key takeaway out of the article is that you can no longer assume 1 char is equal to 1 byte. In ASCII this is true and makes a lot of string manipulation in LabVIEW easy, you can switch between characters and byte arrays easily. The number of characters is the same as the number of bytes so that as you iterate over the elements of the byte array, you are iterating over the characters. In Unicode, this is not so.
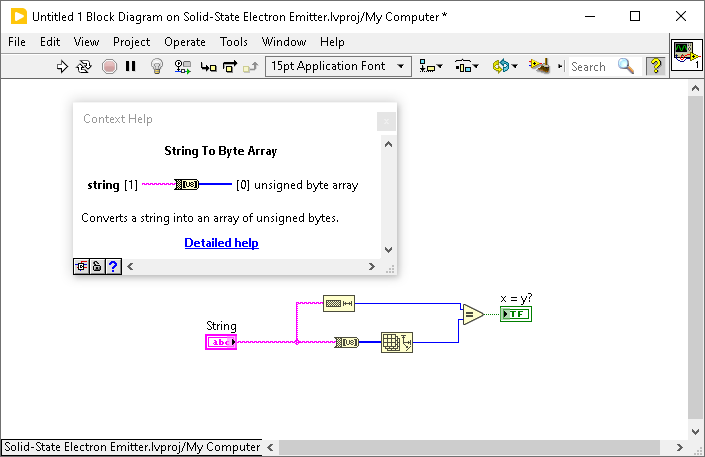
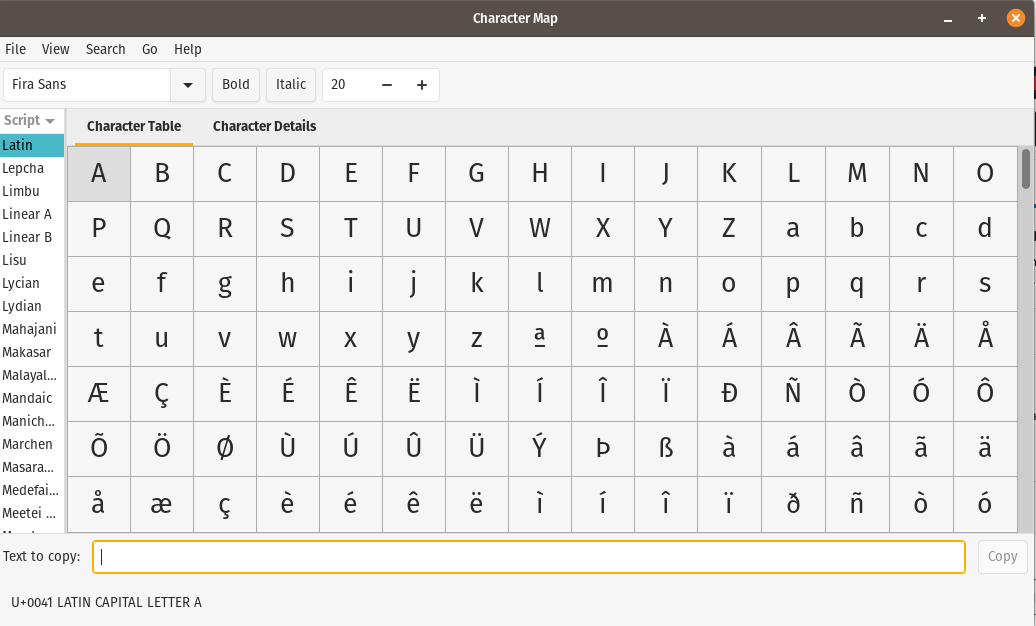
In Unicode, each character is assigned to a code point. As you can see in the image below A is assigned to U+0041. Depending on the encoding used a codepoint could be stored as a single byte or multiple bytes. Encodings such as UTF-8 allow for codepoints that are stored in single bytes as well as allowing other code points to take up multiple bytes. So the length of the string in characters is not the same as the number of bytes.
If you want more information on using Unicode in LabVIEW, here is a good starting point.
https://forums.ni.com/t5/Reference-Design-Content/LabVIEW-Unicode-Programming-Tools/ta-p/3493021
