Command Query Separation of Class Methods

In reading Micheal Feather’s book on Legacy Code, on page 147 it mentions the idea of command and query separation.
A method should be a command or query, but not both.
Working Effectively with Legacy Code page 147
A command is a method that can modify the state of the object, but doesn’t return a value.
A query is a method that returns a value but does not modify the object.
This seems kind of academic. It’s kind of hard to see why it is important. Let’s look at how we can apply this in LabVIEW first and then it will become more obvious why this technique is useful.
Applying it to LabVIEW
The basic idea is to separate methods that modify the object’s private data (commands) and methods that simply return values but don’t modify the object (queries). How do we do that in LabVIEW? How can we make it obvious which methods actually change the object’s private data and which ones don’t? The easiest way to do that is to only pass an object out of a method if it modifies the class private data.
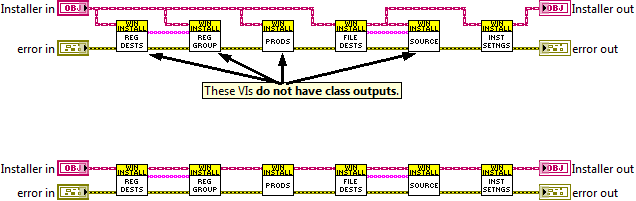
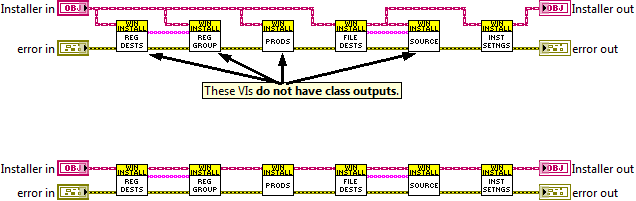
As you can see from these images, it’s really easy to tell from the top image that there are only 2 VIs that could modify the class data. Whereas in the bottom case, we would have to open up all 6 VIs.
This Looks Familiar
If this idea seems familiar, it’s probably because you have watched Darren Nattinger’s, Put An End To Brainless Programming in LabVIEW presentation. I actually stole the snippets above directly from Darren’s presentation. (Hopefully, he doesn’t mind). In that presentation, Darren rails against the classic railroad track pattern in LabVIEW (pun intended) and advocates for not passing an object out when a method does not alter the object.
Why is it important?
So why is this technique important? Well as Darren points out in his presentation, it helps immensely in troubleshooting and debugging. If you have a long track of rail-roaded VIs, and at the end of this railroad track your object contains some incorrect data, where did it come from? You have to look inside every VI, because they all have a class in and out, so they have the potential to change the class data. However if some of the VIs do not have a class output, then you can simply ignore them, because there is no way they can alter the class data. This saves immense amounts of debugging.
How does this apply to legacy code?
Well one thing you could do is to go through the classes in your legacy code and take all the VIs that do not change the class data and remove the class output. This will break your calling code, so you do want to be careful here. But if you can identify all the callers, you can simply rewire them. Now as you are changing things and doing other refactorings, you’ve cut down on the number of VIs you have to consider when tracking down why the class’ private data contains incorrect values.
What about error wires?
You could also consider removing the error wires as well if the method in question is a simple accessor or some other simple algorithm that couldn’t possibly generate an error. Again this will break your callers so be careful, especially because oftentimes error wires are used to ensure execution order. You should be aware of that.
Need Help?
If you have some legacy code that you need help taming, give us a call and we’d be glad to talk about how we can help.
