Automatic Versioning

At the GLA Summit recently minted LabVIEW Champion Felipe Pinheiro Silva gave a 7×7 on versioning. It was interesting. Be sure to take a few minutes and watch it when the video is released. I do things slightly differently. I learned my method from another LabVIEW Champion, Stefan Lemmens. He’s part of our LabVIEW Mastermind Group and at one of our meetings we discussed versioning and he shared his method with us. I do a modified version of what Stefan does. I thought I’d write a little bit about it to add to the discussion.
Semantic Versioning
What do I mean by versioning? I am talking about semantic versioning. Every build gets assigned a series of 4 numbers: Major, Minor, Fix, Build. A change in the major number indicates breaking changes. A change in the minor number indicates non-breaking changes. A change in the fix number, just means a bug was fixed. A change in the build number means we made a new build.
Semantic Versioning helps your users make decisions when upgrading. They know a major upgrade is likely to break things, while a minor upgrade might break things and a fix or build upgrade should be a non-issue.
Why is versioning important?
Versioning is an important part of software development. The beauty of software is that it is malleable. Once it is built we can tweak it and add features very easily. The problem with that is that when it comes time to debug issues, we need to know exactly what version the customer is running. We may need to access that version of the source code to reproduce the bug or maybe that bug has already been fixed in a new version and they just need to upgrade. Having a version number also helps customers manage their configuration. If they have multiple machines, they can make sure they are all running exactly the same code.
Displaying the version
When you version an executable build in LabVIEW, you can view the version using Windows Explorer. If you build an installer, you can also see the version of the installer (not necessarily the same as the exe – I generally recommend you keep these the same) in Windows add or remove programs.
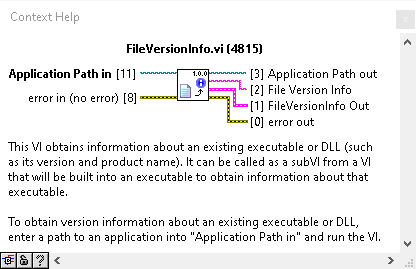
I find it very useful to display the version of the executable on the front panel of the application. It makes it quick and easy for your users to find what version they are running. There is a VI built into LabVIEW that will grab the version for you. I’ve also seen people have constants on the block diagram that get updated either manually or via scripting before building the code. I prefer to pull it from the executable itself.

Setting the version
So how do we set the version when building things in LabVIEW? All buildspecs in LabVIEW contain a version field. All of what I am about to talk about also applies to VIPM packages, although the interface is different.
Manually
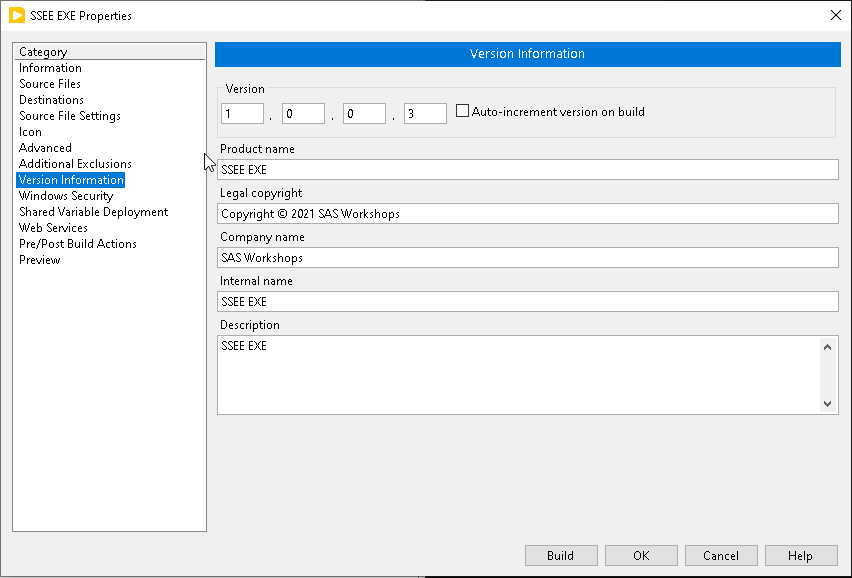
The obvious way is to set the version field is in the build specification properties window. You can easily do this before you make a build. There is an auto-update checkbox. If you set this, the major, minor, and fix will stay the same, but the build will increment every time you build it. Or you can manually set all 4 numbers each time.
API
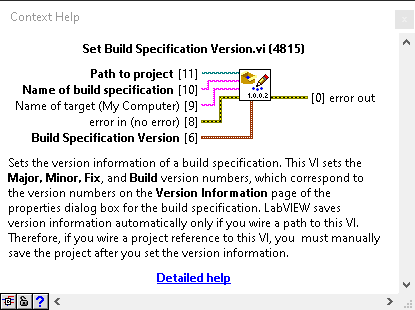
For our purposes though, we are going to use the API. We are doing that because we want to take advantage of Continuous Integration. We want to be able to run builds automatically when we push our code. When we do, we use the Build API and it has an input for setting the version number. Whatever script we use to call the API, can just set the build number before building.
Calculating Build Numbers
The question is how do we calculate the build number?
Goal
To start out with, let’s outline what we are trying to accomplish. Everytime we make a commit and push it to the server, the server is going to build our project. We need a build number to provide to the server before we build. Not all builds are going to get released. Some will fail (hopefully not, but it happens). Some will build but still not be ready for release. These are test builds. We don’t care about those as much. We do care about the releases. Each released build should have a unique version number and given a version number that has been released, we should be able to easily pull the source code that went into that version out of the repository.
Theory
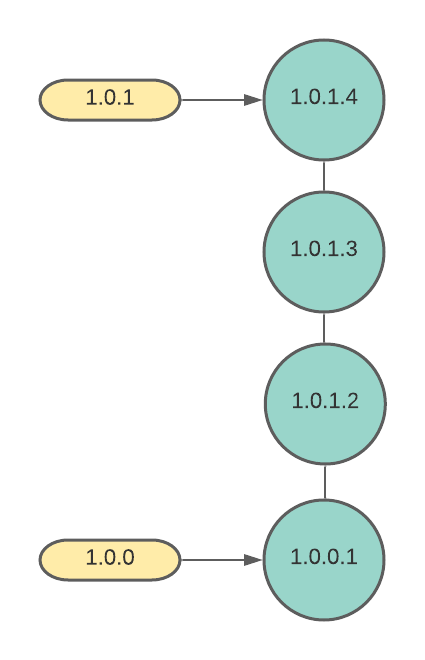
The theory of how we calculate the version number for a commit is quite simple. Every time we make a release we tag it with the first 3 numbers. This is a manual decision that we make based on the scope of our changes, whether it is a major, minor, or fix release. Every commit that is not tagged is a test build. For test builds, the first 2 numbers are the same as the most recent tag, and the fix number is incremented. For both release and test builds, the build number is simply the number of commits in that commit’s history.
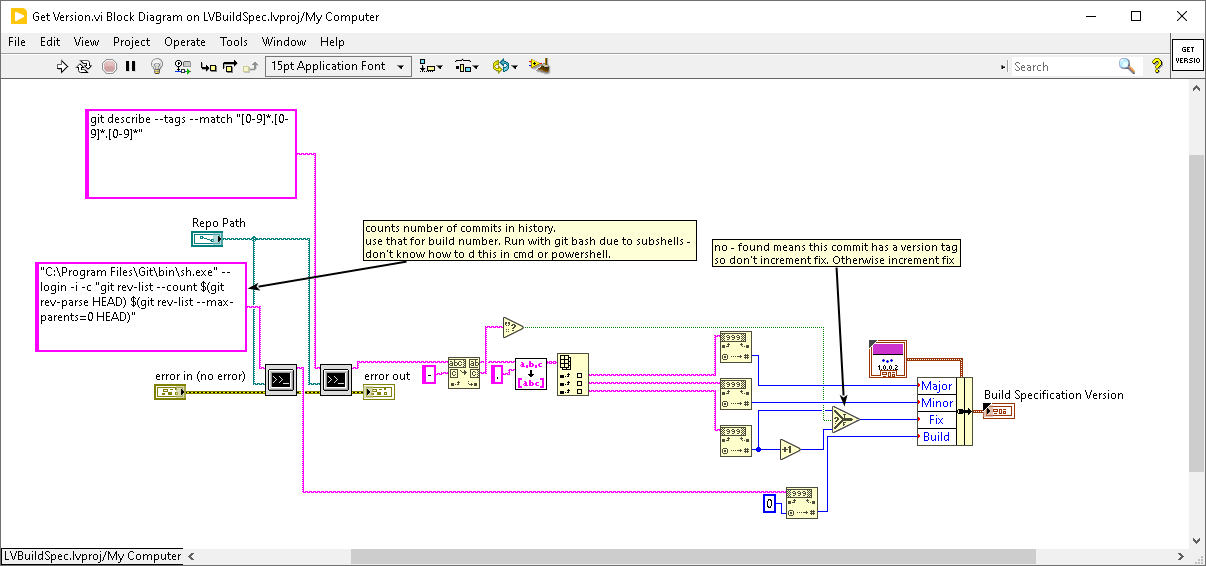
Code
Here is the code to do the calculation. It is uses the cmd exec function in LabVIEW to execute some Git CLI commands and then parses the output. The big long command, calculates the number of commits in the history. The shorter one searches for tags that match the x.x.x pattern, where x is a number. It returns the closest matching tag in the history and tells you how many commits back it is. So a return value of 1.1.1-2 means that the tag 1.1.1 is 2 commits back. If there is no dash, that means the tag points to the current commit, in which case we don’t update the fix number. The code is in a public Gitlab Repo.
Not a Perfect System
Some of you who are more familiar with Git might say, “Well wait! Those test builds are not guaranteed to be unique. If 2 people checkout v1.0.0 in different branches and each make 1 commit and then build, they will both have the same version number.” That’s true, but those are test builds and we generally don’t care a whole about them. If a developer creates a test build to test something out, they know what went into the build. They don’t need the version number to tell them that. We are not releasing those builds to customers. What we are releasing to customers are the tagged versions and those are unique in my case, because I practice trunk-based development. Official releases always get built on the build server. And when I want to get an official release to give to a customer I get it from the build server.
Another challenge is that GitLab CI in particular makes a shallow clone (depth=50) by default. That messes up the calculation of the build number once you get over 50 commits in the repository. You can reset the build number after each release, and that helps, but you can’t guarantee that you won’t go over 50 commits before the next release. So the solution is to override that behavior by setting the GIT_DEPTH to 0. See the yaml below. If your project is huge and has a lot of history, doing a full clone might take a while, but for small projects, it is not an issue. And you only have to do it for the build job, the rest of your jobs can do a shallow clone.
build:
variables:
GIT_DEPTH: 0 # this is needed so build numbers calculate correctly. It is based on number of commits in entire repository.
Finding a System that works for you
What I’ve just shown you is how I do versioning. I’m not claiming it is the best way, just what works for me. I suggest you take these ideas along with Felipe’s presentation and come up with a system that works for you. I do recommend you come up with a way to automate it so that every commit always generates the same version number. I also recommend always building on the same machine and versioning it’s configuration somehow, so you can guarantee that when you check out a commit and build it, you are getting not only the same version but the same exact binary.
If you need help setting that up, let’s talk. Use the button below to schedule a call and we’d be glad to talk about how we can help you.
