A case for sets

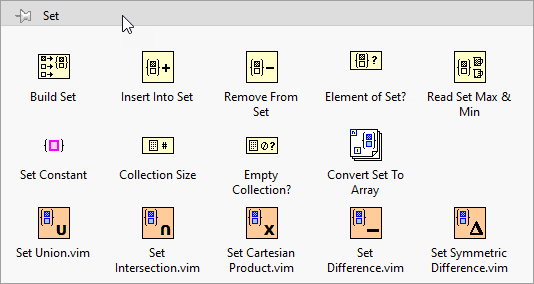
Back in LabVIEW 2019, NI introduced both sets and maps. Maps became immediately popular. They should be. They are very useful constructs. However, sets seem to have gotten much less attention. In some ways, they aren’t as glamorous, but they do offer some advantages over arrays. To me, these advantages really come into play when writing unit tests.
So here’s an example unit test from my tdmsheaders project, to help illustrate. In this example I am testing that if I try to read a key from a tdms file and the key does not exist, that it is handled correctly. What should happen is that the Missing Keys Boolean should be true and the name of the key should show up in the array of Missing Keys. I combined those 2 checks into a Custom Assertion Method, hence the 2 block diagrams.
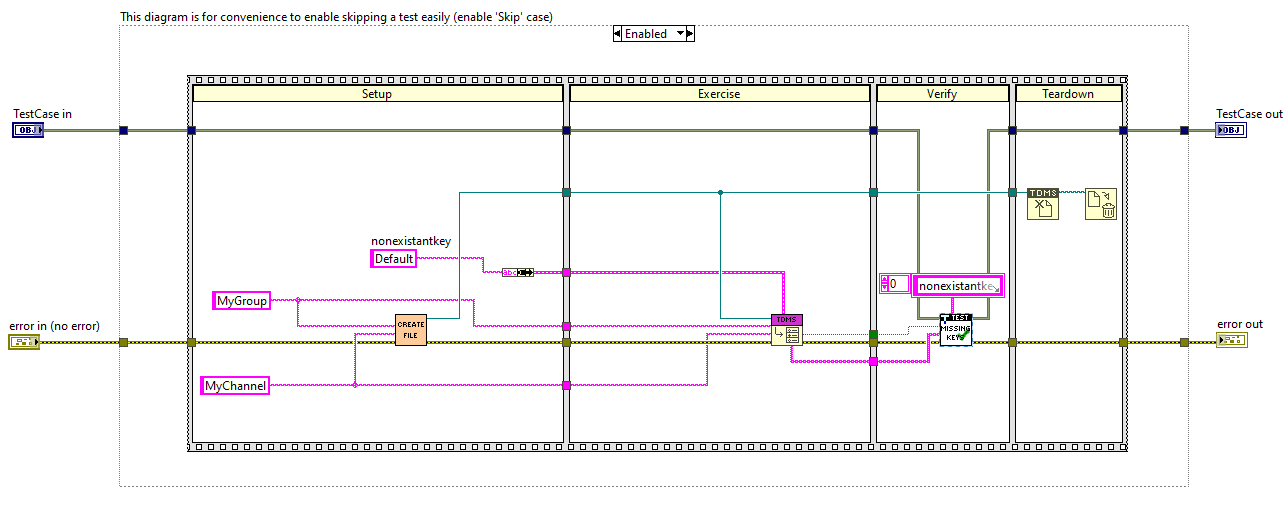

Now you’ll notice that the Missing Keys output is an array. Ok, my naming is not entirely consistent here – the input to the custom assertion should be named missing keys, not missing properties. The Should be Missing input is also an array. The first thing I do is turn them both into sets. Why? Because I don’t care about the order.
What about the order?
Now in this simple case, I only have one missing key, so there is no real order, but what if I had a test that was missing 3 keys? Do I really care what order they come back in? In this case, no. I just want to make sure they show up somewhere in the array. I can’t just create an array constant and check for equality. For two arrays to be equal, the order matters. The array containing [a,b,c] is not equal to an array containing [c,b,a].
Now if take those same two arrays and turn them into sets, then they would be equal, because sets don’t care about order. They also don’t allow duplicates, which is something you should consider. In this case, there really shouldn’t be any duplicates to worry about.
Don’t unecessarily constrain your code
The problem with using an array is that it unnecessarily constrains your code. In the example above, in my test I could directly perform an Assert if Equal and have an array constant there. I wrote the code so I know that the Read VI goes through the cluster elements in order and so I know the order that output array will have. I can write the test that way and it will pass, but that hinders me in the future. If I ever want to change the algorithm inside my Read VI to read the tags in a different order, it would break my test. Should it? Not as long as the Missing Keys array contains all the Missing Keys. I don’t really care about the order.
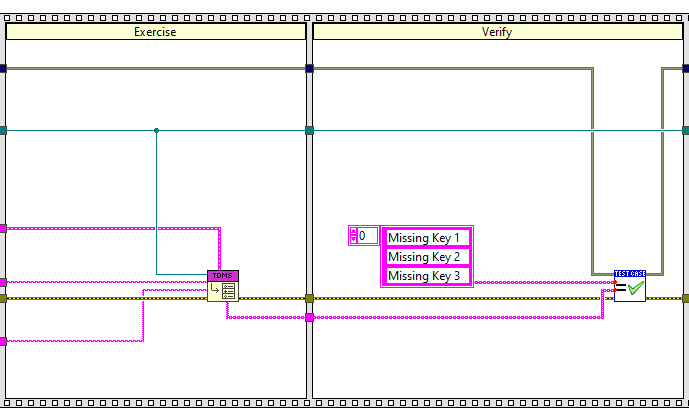
Why does the Read VI return an array instead of a set?
That is a good question and I am not entirely sure why I did it that way. It would probably make sense for it to return a set instead of an array. I do remember thinking about it. I was obviously aware that sets existed, because I used them in the test. Old habits I guess. Perhaps I will go back and change it someday.
The Moral
The moral of this story is that when you return several items and you are considering using an array, consider carefully if:
- The order matters
- It will be possible for there to be duplicates
If the order does not matter and there will not be any duplicates, then you should probably return a set instead of an array. It will make your life easier when writing unit tests and prevent you from overspecifying your code.
